AI Fairness and Causality





Advances in the science and technology of Causal AI—a new category of machine intelligence that can mirror human reasoning—are helping organizations to ensure their AI systems are aligned with human values. In this two-part piece we offer a brief introduction to the problem of fairness in an age of algorithms, and show how Causal AI provides a framework to ensure organizations can have confidence that they are part of the solution.
It’s a problem of today
Imagine a society in which machines make autonomous decisions which impact people’s lives, choosing who has access to basic services, who’s qualified for a mortgage, and whether or not they should be incarcerated. That might sound like science fiction, but it’s the world we’re already living in.
Many of us expected the development of AI to leave a very noticeable footprint in the way we interact with the world, with a clear before and after. But the fact is that AI has crept into our everyday lives in ways we barely notice. It’s been seamlessly integrated into a wide variety of products and services, and so we often don’t realize its prevalence.
Is that working? It depends on who you ask. Some industries have flourished under this wild west of AI development, most noticeably the advertising industry. The ability to generate hyper-personalized recommendations based on deeply intricate profiles of customers has led to a major paradigm shift, compared with the age of TV ads and roadside billboards.
Hyper-personalization isn’t limited to the advertisement industry. Every single possible decision that is being made on the basis of individual characteristics is being tackled by AI algorithms, from lending decisions to assessing a criminal’s likelihood of reoffending. The overall goal seems innocent enough: if we know everything about an individual, shouldn’t we be able to predict these outcomes quite easily?
What do you really know about me?
Sensitive decisions (like choosing who to lend to) pose the following problem for hyper-personalization: Lenders aren’t really supposed to know everything about a customer. As a matter of fact, in many jurisdictions “protected characteristics”—such as gender, race, or religion—cannot be used at all.
The fact that models don’t directly use these protected characteristics doesn’t necessarily mean that they are fair, though. For example, if an AI model uses your address to make a decision and you live in an area where a particular race is overrepresented, then the algorithm can potentially make decisions which are indirectly based on race. Zip codes serve as a proxy variable for race, making the decision unfair.
The consequences of inadvertently releasing an unfair model can be huge. For example deploying a lending model that is discriminating against applicants based on their address can create ethical hazards, reputation damage, and regulatory risks involving fines and even suspension of activities.
While in some cases proxies are direct, oftentimes the source of discrimination can be more subtle. There are commonalities across different groups which can be potentially picked up by algorithms, for instance:
- Minority groups are more likely to work in the gig economy.
- Islam and other religious minorities rely on specific products to replace credit and interest.
- Spending patterns can reveal one’s marital status.
Since AI models generally work as black boxes, it’s hard to interrogate why a sensitive decision was made—the typical explainability methods only focus on “feature importances”, which fail to capture the intricacies in how the combination of different variables is accounted for.
Old or new biases
Another problem in blindly relying on AI black-box models to make decisions is that they are no fairer than the data with which they’ve been trained. Take, for example, an algorithm trained to identify potentially good candidates in a pool of job applicants. The first step in training the algorithm is to show examples of historically successful employees, where success is measured by internal metrics like salary, promotions or seniority.
If the company has a history of only promoting employees of a given gender or race, or there’s a culture of favoring employees that have attended the same college as the CEO, then the algorithm will be by definition biased. It will learn to identify these characteristics in the pool of applicants. The data is the problem!
In this case, the AI model falls short on the promise of its name: it’s not artificial, since it’s just parroting historical human bias; and it’s not intelligent, since it’s too dumb to fix this problem by itself. The idea of the all-knowing, all-powerful AI that would lead to a dystopia has been the source of countless books and movies, from Skynet to HAL 9000. But what if in reality AI is just really, really ignorant, and its stupidity is the source of all evil? Then there needs to be a way to identify and curtail unfair decisions made by AI models.
The 9000 series is the most reliable computer ever made. No 9000 computer has ever made a mistake or distorted information. We are all, by any practical definition of the words, foolproof and incapable of error.
What do terms like “fairness” and “discrimination” mean?
The legal domain distinguishes between two types of discrimination:
- Disparate treatment
Intentionally treating an individual differently based on his/her membership in a protected class (direct discrimination). The aim is to prohibit the use of sensitive attributes during the decision process. - Disparate impact
Negatively affecting members of a protected class more than others even if by a seemingly neutral policy (indirect discrimination). The aim is to ensure the equality of outcome among groups.
Disparate treatment is easy to understand: if I make a decision solely based on a protected characteristic then I am discriminating.
Disparate impact refers to discrimination that isn’t strictly intentional. Although protected characteristics aren’t directly used in the process, there may be other variables which act as proxies for them. Disparate impact isn’t always illegal, provided that the variables used have a legitimate reason to be used.
Take, for example, a fire department. As a job requirement, applicants are required to carry a heavy load up a flight of stairs: this requirement biases against women; a higher percentage of male participants are likely to pass the test. Carrying heavy objects up and down staircases is, however, a necessary requirement for the job—therefore this particular bias is legitimate. Had a law firm required the same test, then it would have been illegal: there’s no legitimate reason why lawyers should need to carry bodies down a flight of stairs.
Algorithms make this equation complicated. While it’s easy to understand how a strength test can be discriminatory in some contexts, it’s far from trivial to assess whether hundreds of characteristics—including all the complex ways they can combine and interact—might lead to unintended discrimination.
Predictions are not decisions: fairness is causal
There is a way to cut through all this complexity, and it’s conceptually very simple. We want to find out if the protected variable (let’s say gender) is influencing the algorithm’s decision. Fundamentally this involves asking the following question:
What would have happened had this applicant been of a different gender?
This is a counterfactual question. A counterfactual requires us to envision an alternative world in which we are able to imagine someone’s gender as being different, while keeping certain characteristics that are important fixed (like their salary or credit history). Changing someone’s gender will naturally lead to a variety of consequences which may not be fundamental for their creditworthiness, but still might be used by algorithms to make decisions.
Furthermore, today’s AI algorithms are focused on predictions alone. Making a prediction is a fundamentally different problem than understanding the impact of a counterfactual—the latter requires us to understand a true chain of causality. (A black-box AI model will use shark attacks to predict ice cream sales. But to make decisions that will ultimately optimize sales, we need to understand the true chain of causality.)
Decisions that involve fairness are no different. We need to understand how changing one variable will affect all others — and how this chain of causality will ultimately percolate to our target of interest.
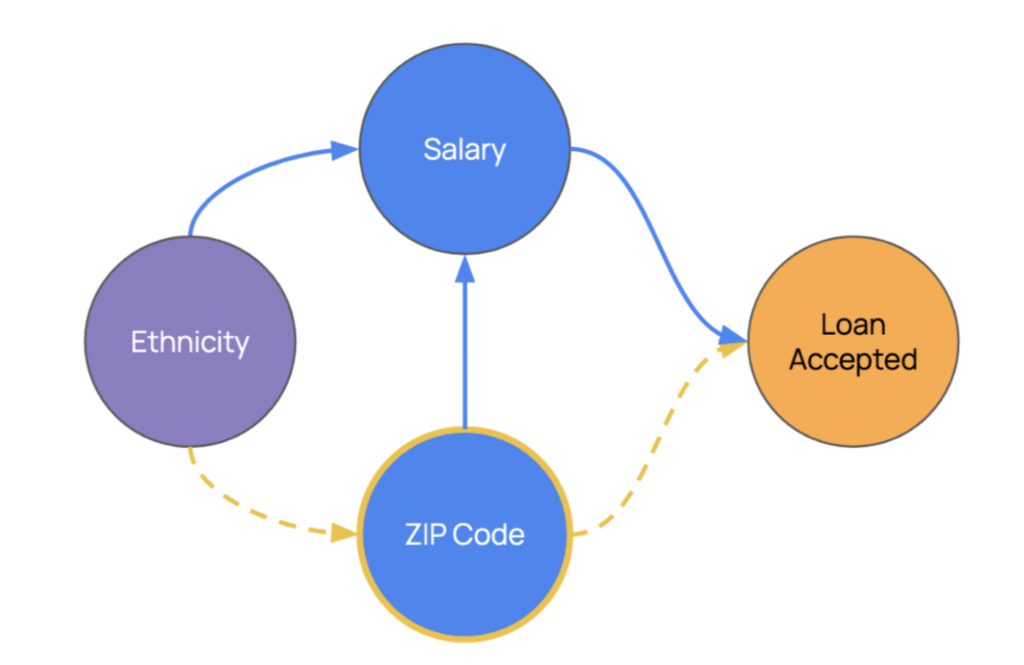
The above diagram is called a causal diagram — it represents not only which variables are associated — but also whether there’s a causal relationship linking two variables. Being able to not only map but quantify the strength of causal relationships is fundamental if we want to understand and certify that decisions are fair. After all, certifying an algorithm is not discriminating requires that we have enough evidence that our actions are not causing an outcome which is unfair.
Conclusion
As more and more organizations are adopting AI models for decisions which leave a lasting impact on society, it’s fundamental that we understand the large-scale consequences of these decisions, and be able to scrutinize them, and most importantly, ensure that they do not create new biases nor propagate existing ones.
In our next post, we’ll explore how Causal AI has already helped organizations certify their AI models as safe, identify sources of unwanted biases, and navigate through a challenging regulatory environment. Setup a call with one of our consultants if you’d like to learn more.