Certifying AI Fairness





causaLens’ research sets out an actionable framework that enables businesses and regulators to test AI systems for bias and discrimination.
Predictive analytics are widely used to automate hiring processes, but they prioritize men and penalize first-generation college graduates. Hospitals use algorithms to triage care for hundreds of millions of patients which have been found to systematically discriminate based on race. Similarly, commercial facial recognition software exhibits skin-type and gender bias.
These are all examples of AI bias — the tendency of algorithms to amplify human biases that are implicit in the datasets they are trained on. AI bias is deepening existing disadvantages in society, according to a Pew Research poll of 1,302 experts.
Policymakers are attempting to grapple with this emerging threat, which has rapidly become an urgent legal issue across the globe. The Algorithmic Accountability Act and Racine legislation in the US, “FEAT” principles in Singapore, and fairness guidelines in Europe and the UK, are all prominent examples of an incoming wave of proposals and new regulations.
But regulators are lacking practical guidance on how to apply abstract principles of “fairness” and “accountability”. “We need much more specific pieces of regulation that tell us how to operationalize some of these guiding principles in very concrete, specific domains”, say researchers from NYU’s Center for Responsible AI.
Correlation-based machine learning exacerbates the problem. Among other fundamental problems these systems are typically “black boxes” that businesses and regulators cannot scrutinize.
Enter causaLens’ latest research paper, forthcoming in Proceedings of AAAI ’22. The paper, co-authored by causaLens’ Hana Chockler and Prof. Joe Halpern of Cornell University, provides regulators and businesses with an actionable framework for certifying that AI systems are fair — even when they are black boxes.
Going Causal
Like much of the most promising cutting-edge research in AI bias (see The Alan Turing Institute’s work on counterfactual fairness and DeepMind’s research on causal Bayesian networks), Chockler and Halpern’s paper takes a Causal AI approach.
One of the challenges of tackling AI bias and promoting fairness is formally defining these concepts. Researchers have proposed a vast number of definitions of fairness (21 by one count). Many of these definitions attempt to define fairness in terms of “parity” (i.e. equal treatment or outcomes) for people from different demographic groups. Troublingly, the different definitions are difficult to verify in the real world and are known to be incompatible with each other.
Causal AI approaches are simpler — roughly speaking, the idea is to check whether sensitive or protected characteristics (like race, gender, religion, and so on) are influencing the algorithm’s decisions. If not, then the algorithm is fair.
Towards a framework for certifying fairness
To see how this works, take an illustrative example of a bank using a ML algorithm to make mortgage loan approval decisions. Suppose the bank has a dataset that includes the following variables — gender, salary, loan_amount.
How can the bank ensure its algorithm is fair? The naive approach of simply deleting gender from the dataset (“fairness through unawareness”) doesn’t work, because the algorithm recovers the withheld information from salary, which continues to correlate with it.
Chockler and Halpern’s starting point is to recognize that there are variables the regulator must allow the bank to use as a business necessity, as well as variables that can’t defensibly be used. They split the data into three categories:
- Sensitive variables. Features that the bank shouldn’t use, either by law or because they pose an ethical hazard (e.g. gender)
- Allowed variables. Features the bank can defensibly use to conduct its business, even if they are correlated with the sensitive variables (e.g. salary)
- Everything else. The bank collects a lot of data: answers directly given by the applicant on their application form, data scraped from websites and metadata. Black-box algorithms, especially deep learning and other representation learning systems, may be using this information in ways that humans cannot understand.
For Chockler and Halpern, the bank’s software is fair provided that changing the values of the sensitive variables has no impact on the decision, if all the allowed inputs are kept fixed. It’s easiest to see how this definition is cashed out by drawing a causal diagram:
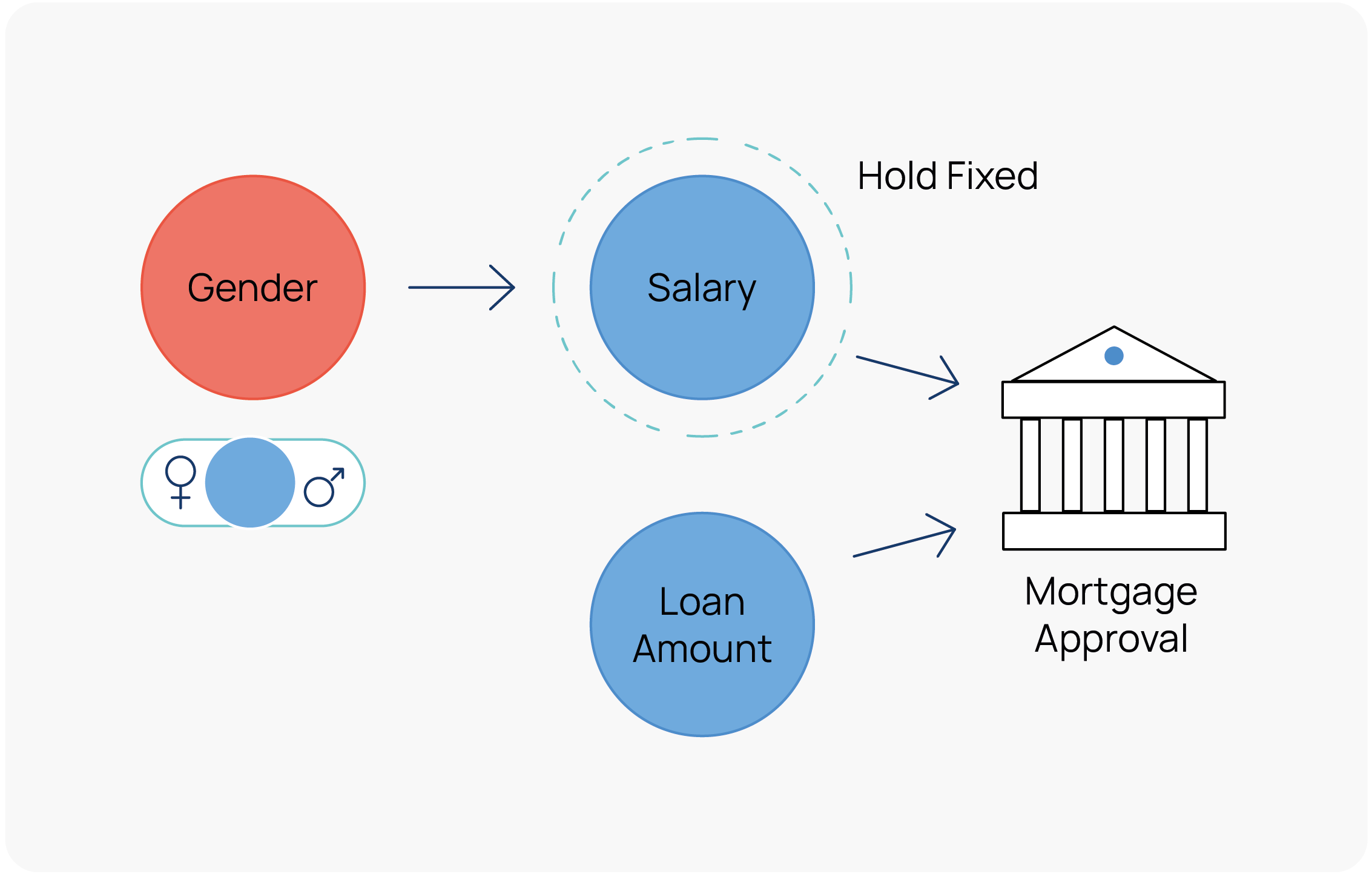
If we toggle the gender of an applicant (so instead of Bob applying for a loan, it’s Alice), and hold the salary fixed, then the system is certified as fair so long as the decision doesn’t change. What this achieves is that it guarantees that there isn’t some hidden pathway from the sensitive variable (gender) to the decision, mediated by one of the non-allowed variables. This is crucial because it provides assurance that the sensitive variables have zero unsanctioned influence on the loan decision. Note that it is only Causal AI that can make these kinds of counterfactual inferences with any confidence.
How practical is this certification process? The bad news is that the process is “co-NP-complete”, meaning that certifying a model as fair may in some cases be too time-consuming for the bank and regulators. The good news, as Chockler and Halpern prove, is that in practice it is computationally inexpensive, and therefore easy, to certify that an algorithm is fair with respect to any given individual applicant.
The best way for businesses to ensure their AI systems are fair and compliant with an evolving body of discrimination law is to adopt “glass-box” Causal AI models at the outset. As causaLens’ latest research shows, Causal AI methods can also play a critical role in reliably regulating black-box machine learning models. Learn more by reading the full research paper here.