- Blog
Explainable AI (XAI) doesn’t explain enough





Why does explainable AI matter?
Explainable AI (“XAI” for short) is AI that humans can understand. To illustrate why explainability matters, take as a simple example an AI system used by a bank to vet mortgage applications.
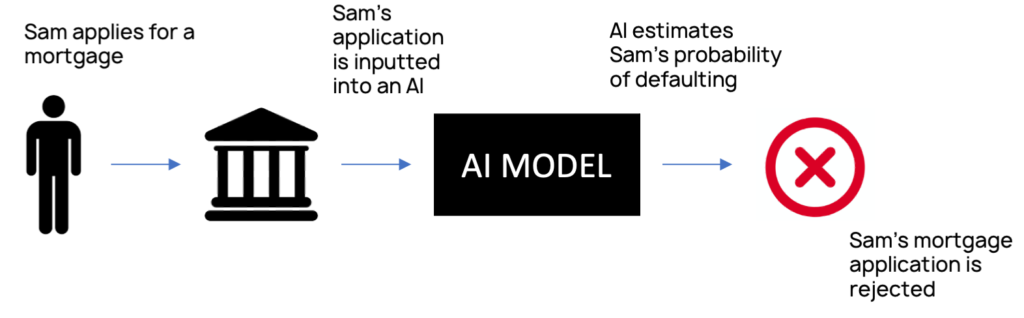
There are a wide range of stakeholders that have an interest in this model being explainable:
End users affected by AI
Sam may want to contest the AI’s decision, or check that it was fair. End users have a legal “right to explanation” under the EU’s GDPR and the Equal Credit Opportunity Act in the US.
Domain experts & business analysts
Explanations allow underwriters to verify the model’s assumptions, as well as share their expertise with the AI. Analysts can also learn new insights from an explainable AI system, rather than just blindly following its recommendations.
Data scientists & product managers
Explainability enables tech developers to troubleshoot, debug and upgrade their models, as well as innovate new functionalities. Without explanations, if the model makes lots of bad loan recommendations then it remains a mystery as to why.
Regulators & governments
Incoming regulations in the EU demand explainability for higher risk systems, with fines of up to 4% of annual revenue for non-compliance. causaLens have provided expert commentary on the new regulations — read more here.
Canada is also issuing legally binding private sector regulations mandating explainability, with fines issued for non-compliance. The FTC in the US is clamping down on AI bias and demanding greater transparency. The UK government has issued an AI Council Roadmap appealing for greater AI governance. More broadly, 42 governments have committed to principles of transparency and explainability as part of the OECD’s AI Principles framework.
Managers & board members
Business owners and board members need to ensure that explainable AI systems are compliant, trustworthy and aligned with corporate strategy.
The example above relates to mortgage applications, but explainability matters in almost every enterprise AI use case, especially those that involve some element of risk. In a nutshell, explainability enables a wide range of stakeholders to audit, trust, improve, gain insight from, scrutinize and partner with AI systems.
How do machine learning algorithms provide explanations?
Today’s AI systems generally acquire knowledge about the world by themselves — this is called “machine learning”. A drawback of this approach is that humans (even programmers) oftentimes can’t understand how the resulting machine-learnt models work. In fact, today’s more sophisticated machine learning models are total black boxes.
Current XAI solutions take these powerful black box models and attempt to explain them. The standard approach is “post hoc” (“after the event”) explainability — this often involves building a second model to approximate the original one.
There are a huge number of XAI approaches, however two are especially popular: LIME and SHAP. Let’s briefly sketch how LIME and SHAP work, at a conceptual level.
Local Interpretable Model-agnostic Explanations (LIME) probes the black box model by slightly perturbing the original input data, and then records how the model’s predictions change as a result. This creates a synthetic dataset. LIME then simply trains a white box model, like a linear regression, on this synthetic dataset to explain the original prediction.
SHapley Additive exPlanations (SHAP) learns the marginal contribution that each feature makes to a given prediction. It does this by permuting through the feature space, and looking at how a given feature impacts the model’s predictions when it’s included in each permutation. Note that SHAP doesn’t look at every possible permutation, because that’s too computationally expensive — it just focuses on the ones that convey the most information.
What’s wrong with post hoc explainability?
LIME and SHAP can help to lift the lid on black box models. But these and other similar methods don’t deliver helpful explanations, for many reasons.
Post hoc explanations don’t magically make your original black box model trustworthy
Conventional machine learning algorithms learn lots of spurious and misleading correlations in input data. They also absorb biases that are implicit in the training data. Post hoc explanations can potentially reveal these problems (see the Figure below). They thereby help you to decide whether to trust your model — but they don’t actually make the original model trustworthy.

Building a second model to explain your first model undermines confidence
Explanatory models by definition do not produce 100% reliable explanations, because they are approximations. This means explanations can’t be fully trusted, and so neither can the original model.
Post hoc explanations are also fragile: similar inputs with the same prediction can be given very different interpretations. And “extremely biased (racist) classifiers can easily fool popular explanation techniques such as LIME and SHAP”, finds Harvard research.
Explanations are generated too late in the machine learning pipeline
You only get to find out if your model is safe, fair and compliant after you’ve wasted time building it and putting it into production. This makes your machine learning pipeline riskier and more resource-intensive than it needs to be.
Post hoc explanations fail in dynamic systems
Standard machine learning models routinely break when the world changes. Post hoc explanations provide no guarantee that your model will behave as expected in the future for new data that hasn’t been observed before. You can only explain model failures, due to regime shifts like COVID-19, after the fact.
SHAP makes transparent the correlations picked up by predictive ML models… [However] the assumptions we make by interpreting a normal predictive model as causal are often unrealistic
Scott Lundberg, Microsoft Research
Post hoc explanations lack actionable information
It’s very challenging to change features in a black box model in line with explanations. Typically, in order to act on explanations, users have to completely change their models and then generate new explanations.
Moreover, because explanations are purely correlational, they can’t be directly applied to business decision making or for diagnosing why something happened — this demands a causal model. As one of the researchers behind SHAP concedes, “SHAP makes transparent the correlations picked up by predictive ML models. But making correlations transparent does not make them causal!” They warn that, “the assumptions we make by interpreting a normal predictive model as causal are often unrealistic.”
User research reveals that standard XAI doesn’t provide human-friendly explanations
Post hoc explainability can help engineers and developers to debug algorithms, but it fails other stakeholders’ needs. “There is a gap between explainability in practice and the goal of transparency”, according to research conducted by the Partnership on AI. IBM user research likewise finds that “practitioners struggle with the gaps between algorithmic output and creating human-consumable explanations”.
Why does Causal AI produce better explanations?
Causal AI is a new category of machine intelligence that can discover and reason about cause and effect. AI luminaries, like deep learning pioneer Yoshua Bengio, recognize that “causality is very important for the next steps of progress of machine learning.” Causal AI offers a better approach to explainability.
Causal AI produces intrinsically interpretable white-box models, reinforcing trust
Causal models contain a transparent qualitative component that describes all cause-and-effect relationships in the data, and so there are no problems of trust, fragility or fairwashing. Explanations are always faithful to the model. Causal models don’t require another model to approximate them.
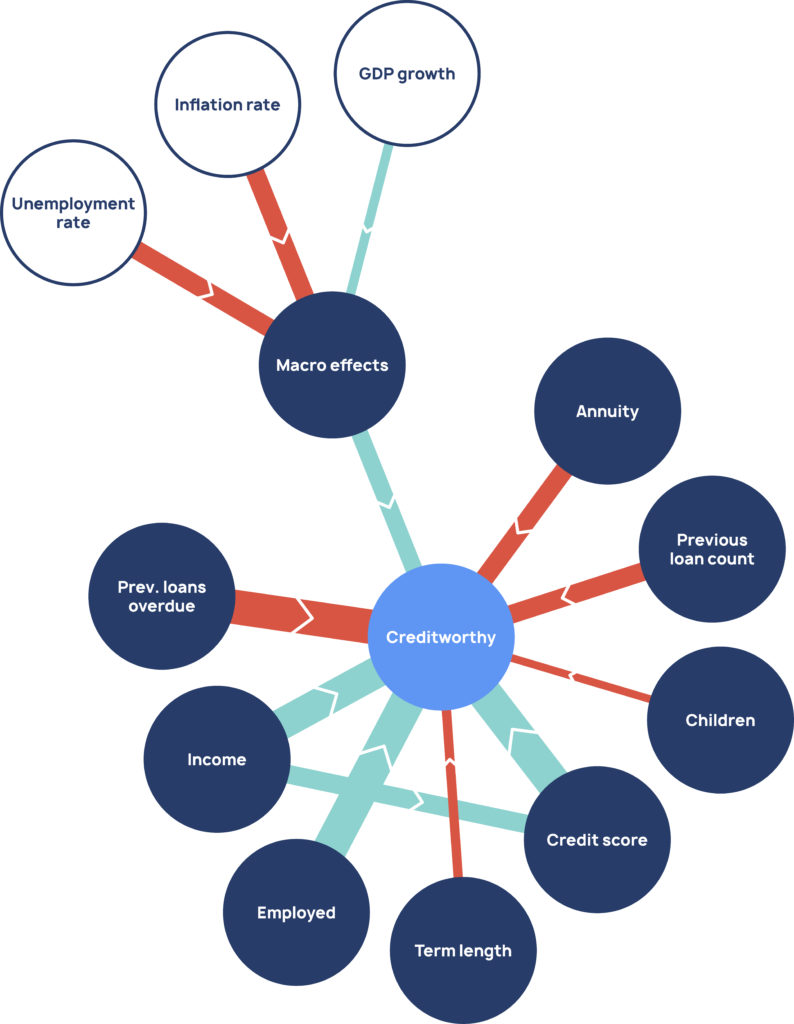
Causal explanations are generated earlier in the AI pipeline, before models are built
Domain experts can restrict models with their domain knowledge and impose fairness criteria by adjusting the causal graph before full model building. This enables safer, more compliant and more controlled applications that behave as intended. In contrast to standard XAI, Causal AI provides ante hoc (“before the event”) explainability that is less risky and less resource hungry.
Causality is very important for the next steps of progress in machine learning
Yoshua Bengio, Turing Award winner and deep learning pioneer
Causal explanations work for dynamic systems
You can guarantee to your stakeholders, including regulators and risk teams, how the model will behave in all circumstances — even when completely novel or unprecedented.
Explanations produce actionable insights
Models can be easily tweaked and tuned on the basis of explanations, which can also be probed by users to simulate interventions and imagine “what-if” scenarios.
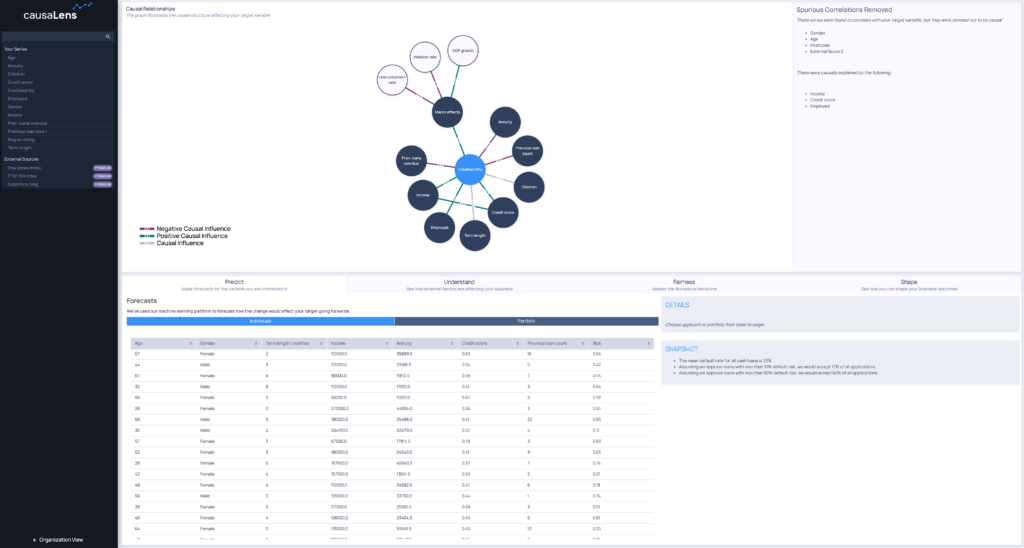
Causal AI produces extremely human-compatible explanations
Humans naturally think in causal terms, and so users can easily interpret and interact with these diagrams. Going beyond predictions, users can assess the causal impact of some policy and interrogate the model by asking what-if questions. These are signature capabilities of Causal AI.
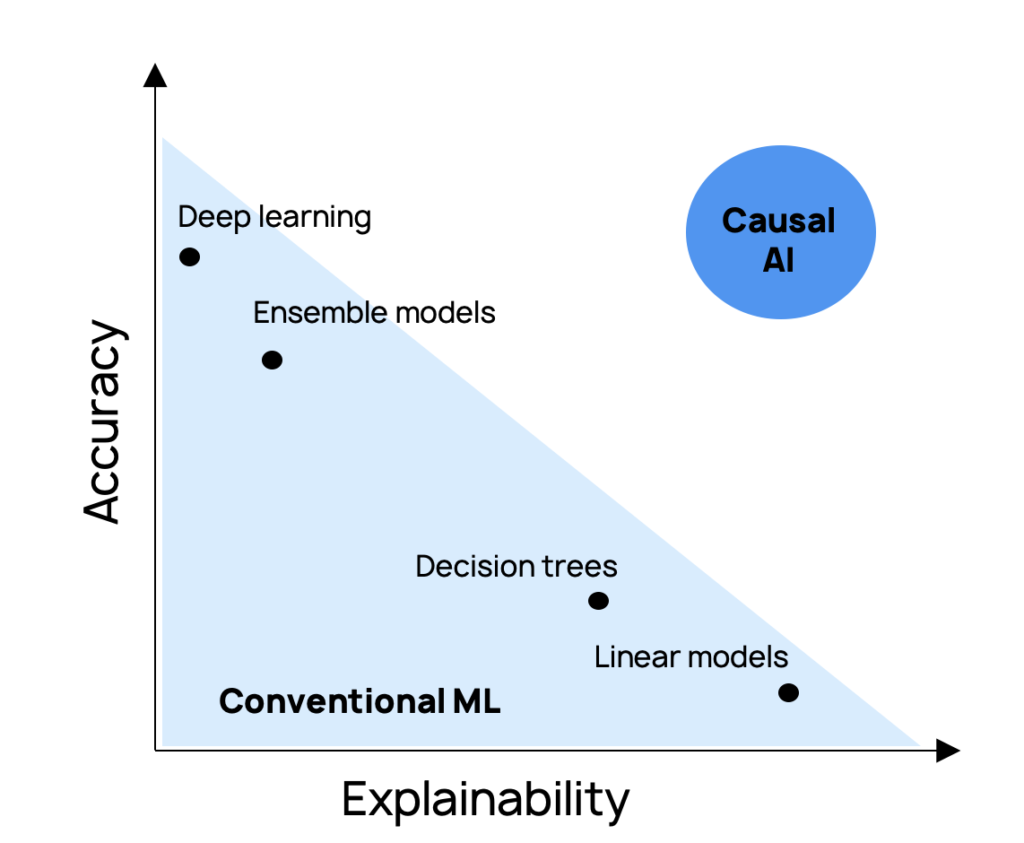
Intrinsic explainability leads to an explainability-accuracy synergy
With conventional machine learning, there’s a trade-off between explainability and performance — more powerful models sacrifice explainability. In contrast, a better causal model explains the system more completely, which results in superior model performance.
causaLens provides next-generation AI for the enterprise. Our technology harnesses Causal AI to build models that are not just accurate but are truly explainable too, putting the “cause” in “because”. Find out how we can help you to better understand and explain your business environment.