Customer Retention for Data Scientists with Causal AI
Predictive insights are not helpful for customer retention unless combined with data-driven prescriptive recommendations for where to engage, what to offer, and how to message.
Retention decisionApp
Overview of the end product presented to business stakeholders
Overview of the causal ai workflow
Summary
Traditional, correlations-based, machine learning approaches often fail to make an impact on improving retention
- they focus on predicting churn but not recommend the optimal next step/intervention
- they lack explainability & trust by marketing executives
decisionOS empowers data scientists to create decision workflows for marketing & sales teams that
- suggest optimal interventions to maximise retention
- are fully explainable through causal graphs and structural causal models
Background
Improving customer retention is a common request received by data scientists. The typical approach involves four steps:
- Build a predictive machine learning model based on observed data about the customer base
- Once a prediction has been made, use a post-hoc explainability method (e.g. SHAP) to understand the importance of each feature within each prediction
- View which features are highly correlated with churners and apply blanket policies to try to prevent churn
- Adhere to the required MLOps processes to ensure model is deployed and maintained in production
This approach brings some statistical rigor to the process of customer retention. However, the approach has some fundamental challenges. Most notably, it is based on historical, statistical associations. It is very difficult to ascertain if these associations are causal or simply spurious. For example, causaLens has worked with datasets which show a positive correlation between discounts offered and churn rate. This is a counterintuitive result and one that a domain expert is likely to question. A subsequent causal analysis of the same datasets reveals that customers who are dissatisfied are more likely to complain, and it is this that results in them being offered a discount. This type of ‘confounded’ relationship is not picked up by a correlational approach.
In addition, statistical associations do not have any notion of the effects of actions. They simply describe the relationship between variables without understanding how they affect each other. Going back to the retention example, it is very plausible that a ‘feature importance ranking’ approach would suggest that offering discounts should no longer be used as a churn reduction mechanism.
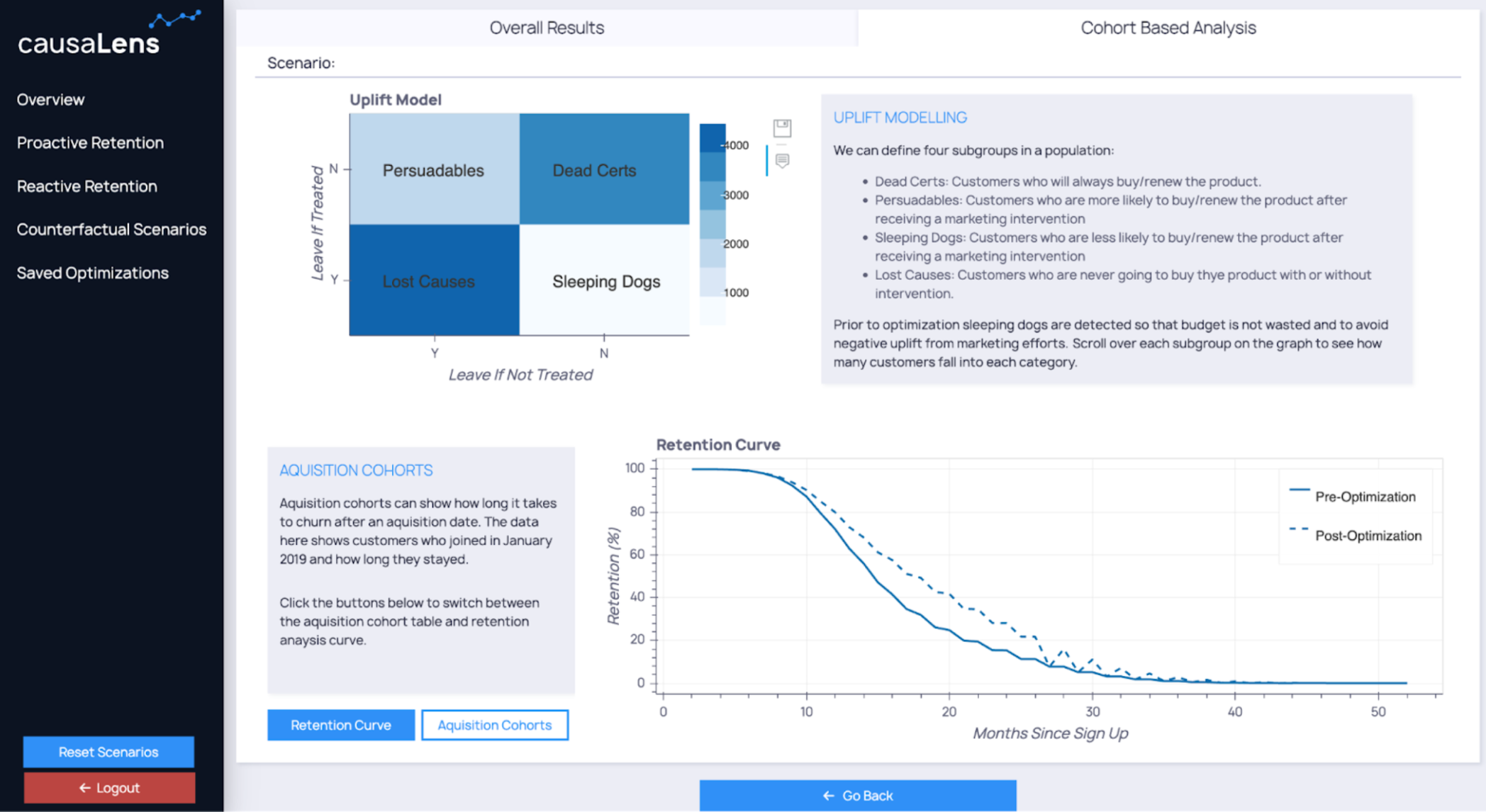
Figure 1: Customer retention decisionApp example
Building Decision Workflows
So, how can a causal customer retention decision workflow be built?
Causal customer retention requires a different approach to the standard data science workflow. Instead of aiming for a black box predictive model with post-hoc explainability, a structural causal model (SCM) is created. Unlike a traditional model which only maps the relationships between each input and the output, an SCM encodes relationships, where they exist, for all variables. See Figure 2.
Because these indirect and second level relationships are modeled, Causal AI enables users to reason about the effects of changes to a process (interventions) and what would have happened in hindsight (counterfactuals). E.g. in the SCM in Figure 2, if the value of A is changed (A = a) it is clear how this affects (or does not affect) all of the other inputs and ultimately the target. For the traditional star-based model, the relationship between A and the other inputs is unclear and it is very difficult to know if this is correctly captured in the black box.
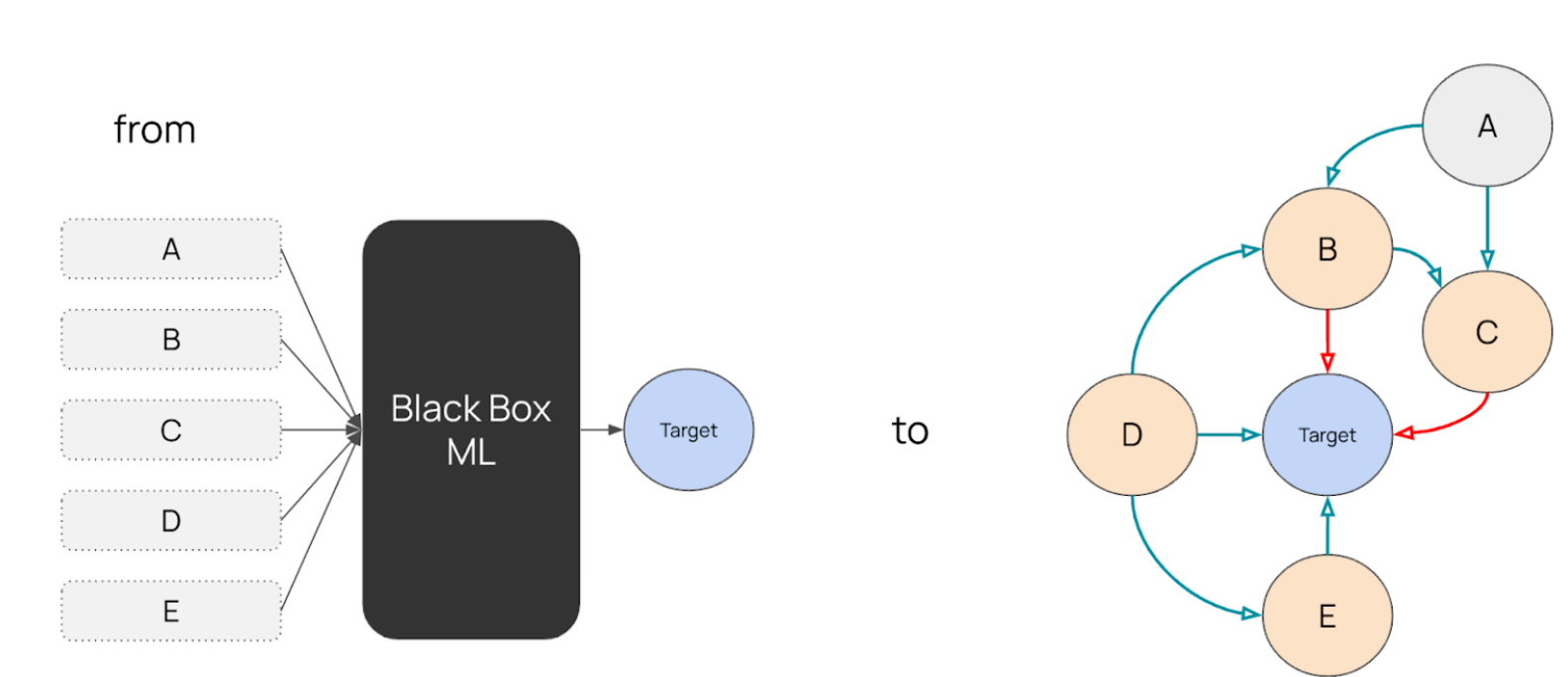
Figure 2: Traditional star-based model vs structural causal model
Our Approach
Causal Data Science workflow
Essentially, with Causal AI, users can understand the exact effect of an action on an individual and therefore what actions can be taken to prevent churn. The causal workflow can be outlined as follows:
- Create a Causal Graph using Human-Guided Causal Discovery to uncover cause and effect relationships within the dataset
- Build an inherently explainable SCM to predict which clients are likely to churn and why
- Use causal decision intelligence to understand the effects of interventions, and provide optimized recommendations for specific actions based on a set of business constraints
- Quickly create and deploy a decisionApp which business stakeholders can interact with to action the recommendations
The approach is outlined in Figure 3.
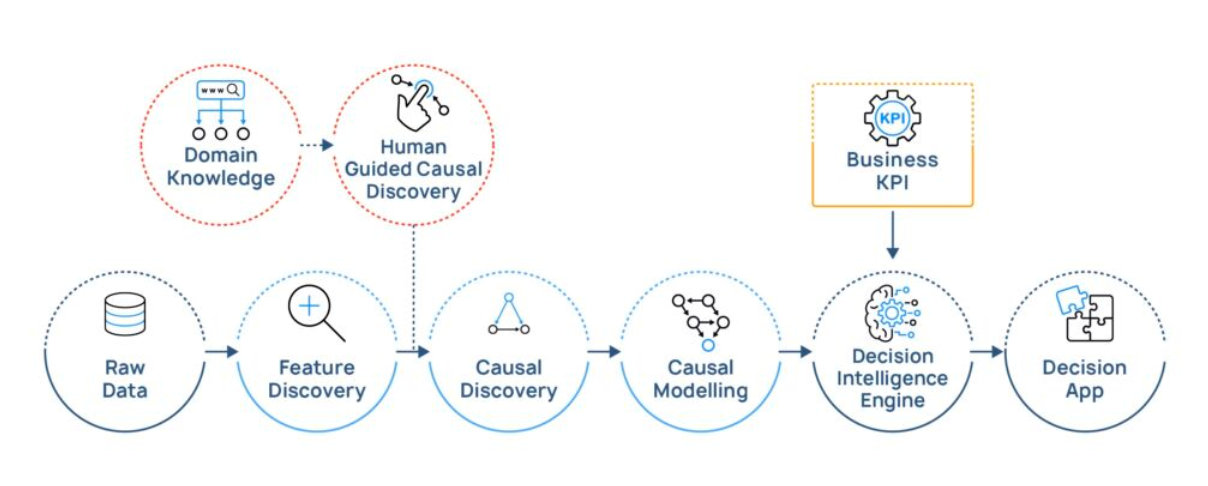
Figure 3: Causal Data Science workflow
Causal Discovery
So, how does this look in practice:
The first step, causal discovery, is carried out prior to building a predictive model. Causal discovery combines algorithmic approaches with domain knowledge to build a causal graph which describes relationships between variables. This is an iterative process which is facilitated by the large range of algorithms, and the Human-Guided Causal Discovery app, which are included in decisionOS.
The algorithmic and domain knowledge components of causal discovery can be provided in either order. In the following example, domain knowledge is immediately provided by an expert once data has been loaded. It is in a tiered format as can be seen in the Human-Guided Causal Discovery App in Figure 4. In tiered domain knowledge, the hierarchy defines which nodes may have a causal influence on others. Nodes in a particular tier are only causally influenced by nodes in their tier or higher tiers.
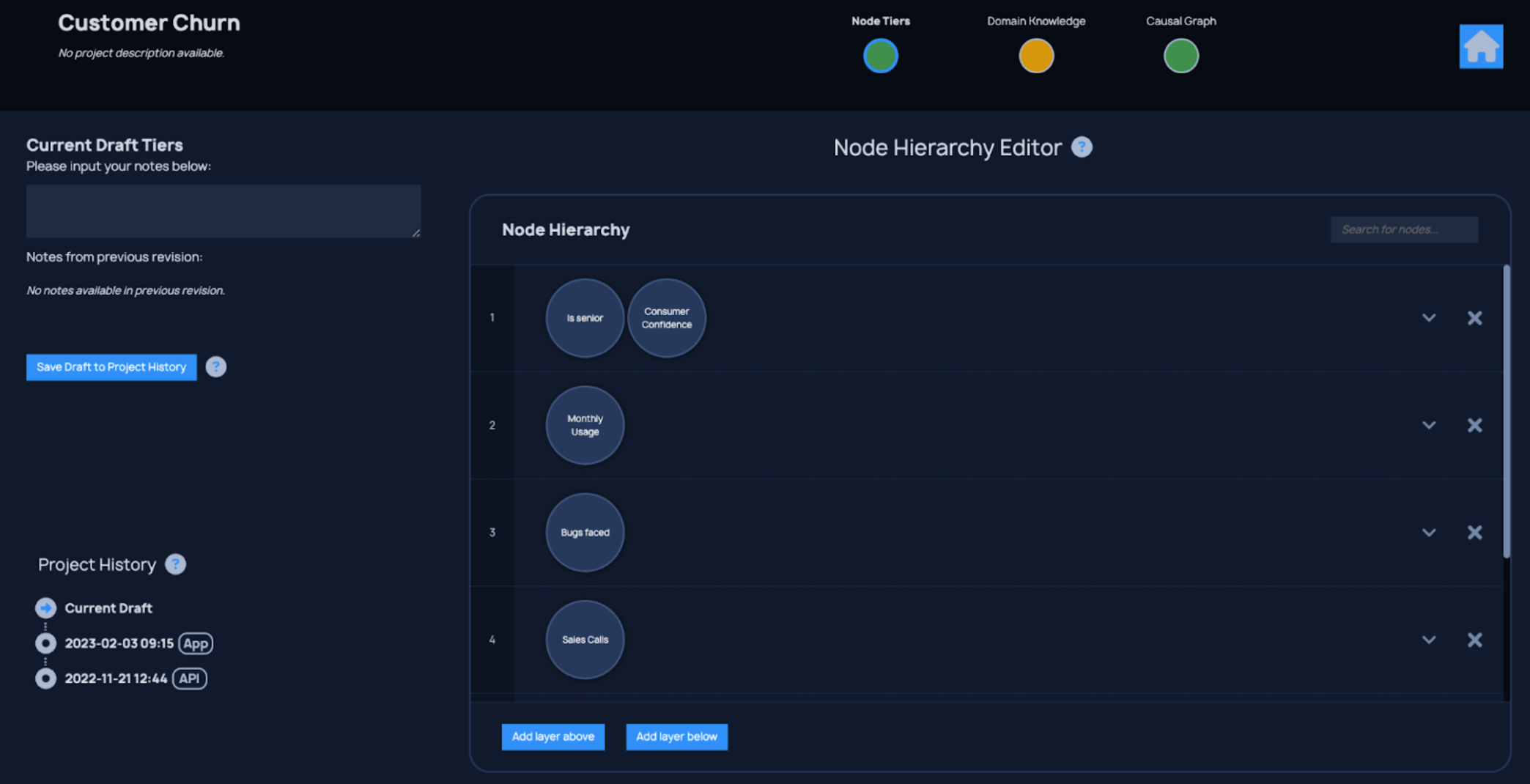
Figure 4: decisionOS Human-Guided Causal Discovery App
Algorithmic causal discovery
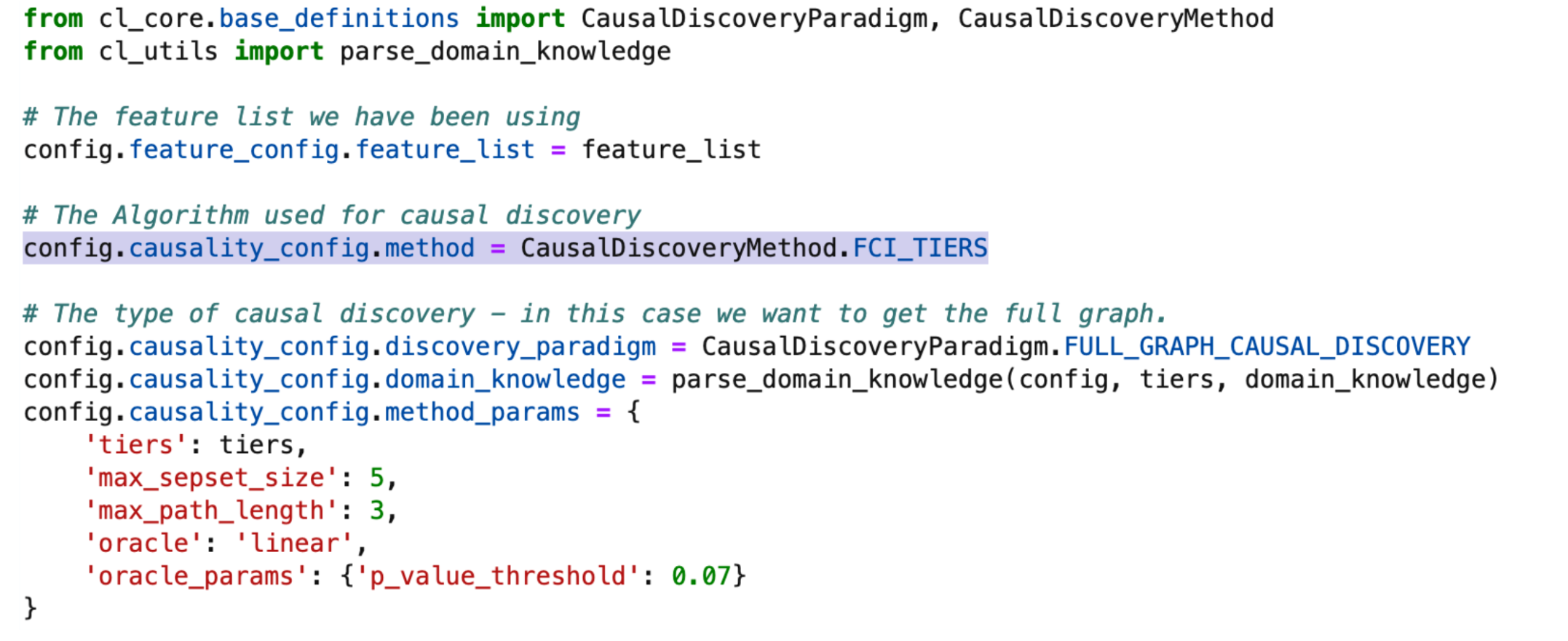
Figure 5: Algorithmic causal discovery in decisionOS
Domain expert review

Figure 6: Presenting a causal graph to a domain expert
Creating the structural causal model
This approach then repeats until both the domain expert and the data scientist are satisfied with the causal graph.
Once this is the case, the data scientist needs to create the structural causal model. At its core this is a predictive model. However, while a standard model uses the input features to predict the target, an SCM uses the causal parents of each feature, in the causal graph, to predict that feature, building up a predictive model of the entire system. This means that the relationships between each of the variables are understood as well as the relationship of each variable to the target.
Benefits of SCMs
SCMs provide a number of benefits compared to standard models:
- Predictions are more robust and fully explainable
- Interventions and counterfactuals can be computed due to the fact that the entire system has been modeled
- Causal decision intelligence engines can be applied to the predictive model. In particular, optimal interventions can can be selected based on constraints provided by the user (e.g. maximum retention budget)
Figure 7 shows how decisionOS allows the model discovery to be easily configured and Figure 8 shows the code which allows the optimal model to be discovered:
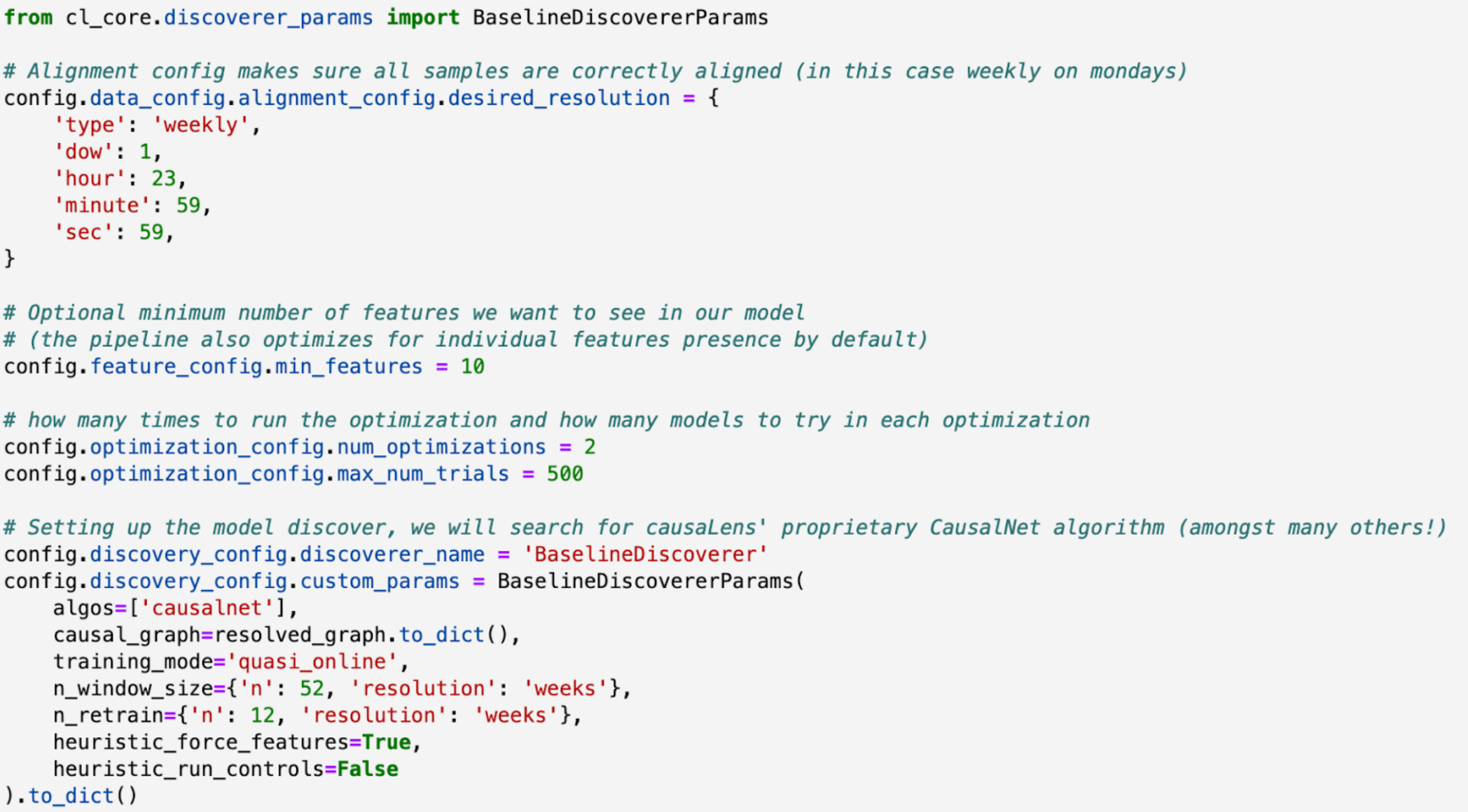
Figure 7: SCM configuration in decisionOS
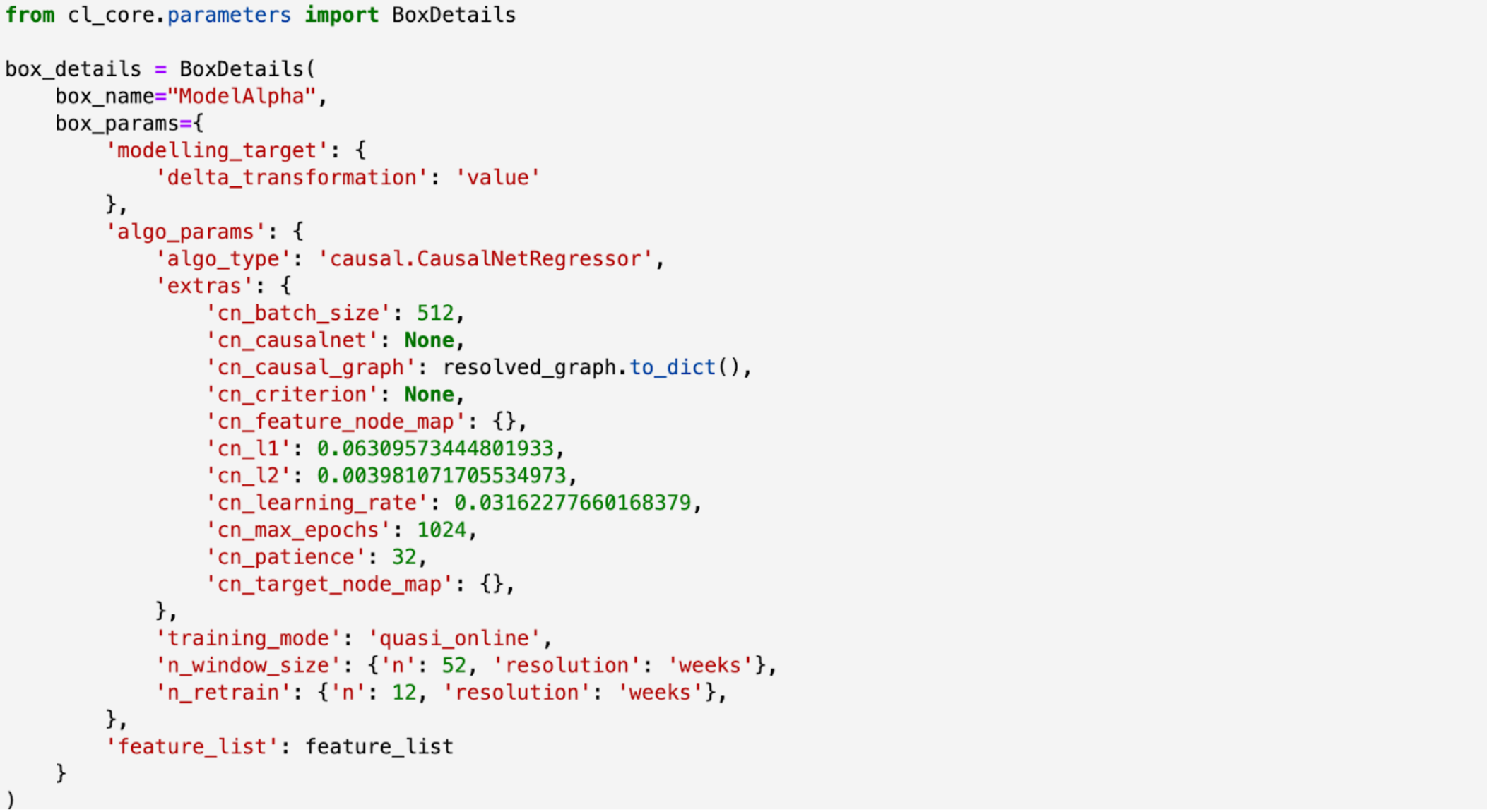
Figure 8: SCM discovery in decisionOS
Decision intelligence engines
The role of decision intelligence engines is to go beyond simple predictions by generating actionable business recommendations. The ability to run interventions and counterfactuals is the basis of causal decision making. In decisionOS, these concepts have been expanded on, to create the following Decision Intelligence Engines:
- Causal Fairness & Bias: Determine how discrimination can occur within your data as you perform interventions and actions
- Causal Effects: Simulate how interventions impact different groups within your data
- Root Cause Analysis: Understand the underlying reasons for why certain outcomes occur
- Algorithmic Recourse: Provide optimal interventions for a given objective
Algorithmic recourse
In the retention example, the focus will be on algorithmic recourse. This allows the user to understand what is the most cost-effective intervention, given a constrained set of possible actions, which will save a subscriber who has been identified as a churn risk. In decisionOS, this works by feeding the Algorithmic Recourse engine, an SCM and a set of business constraints and requesting a given output e.g. Given this budget, reduce the overall churn rate. This can be applied at the individual level (individual recourse), across the full subscriber base or across cohorts within the subscriber base (macro recourse). Figure 9 shows how individual recourse can be configured within decisionOS and Figure 10 shows recommended actions for three customers which have been passed through the recourse engine.

Figure 9: Algorithmic recourse decision intelligence engine configuration
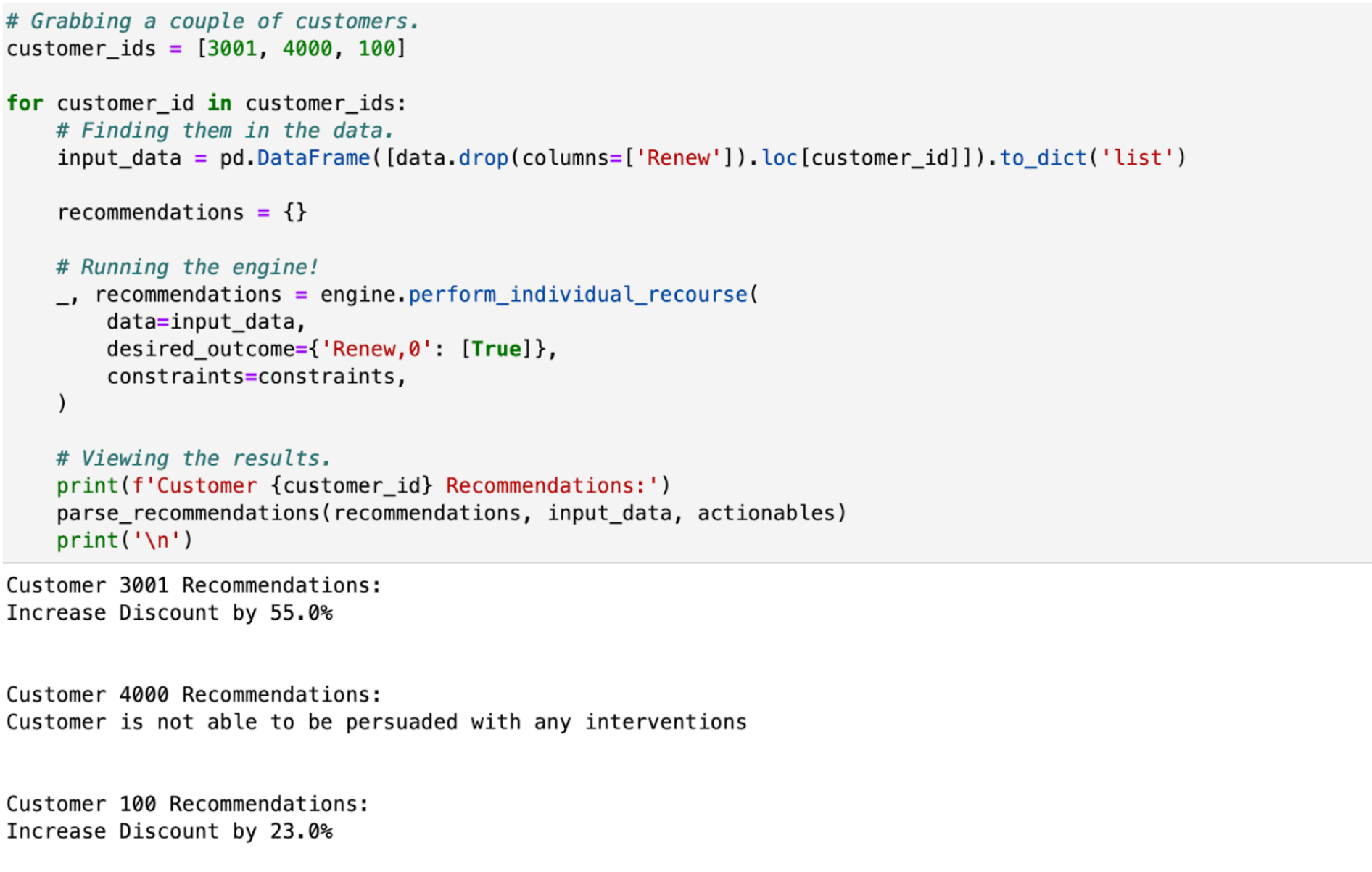
Figure 10: Algorithmic recourse decision intelligence applied to three customers
App building with decisionOS
Similarly to the causal workflow, our app framework, Dara, is a Python-based framework optimized for Causal AI. It contains a number of high-level components which can be pulled in with just a few lines of code.
Additionally, custom pages can be created so that the application can be tailored towards the needs of the business user. decisionApp SDK can also be used within Jupyter environments which enables fast and interactive app development. Figure 11 shows how a decisionApp framework can be created with a single line of code

Figure 11: decisionApp creation with a single line of code
High Level Components
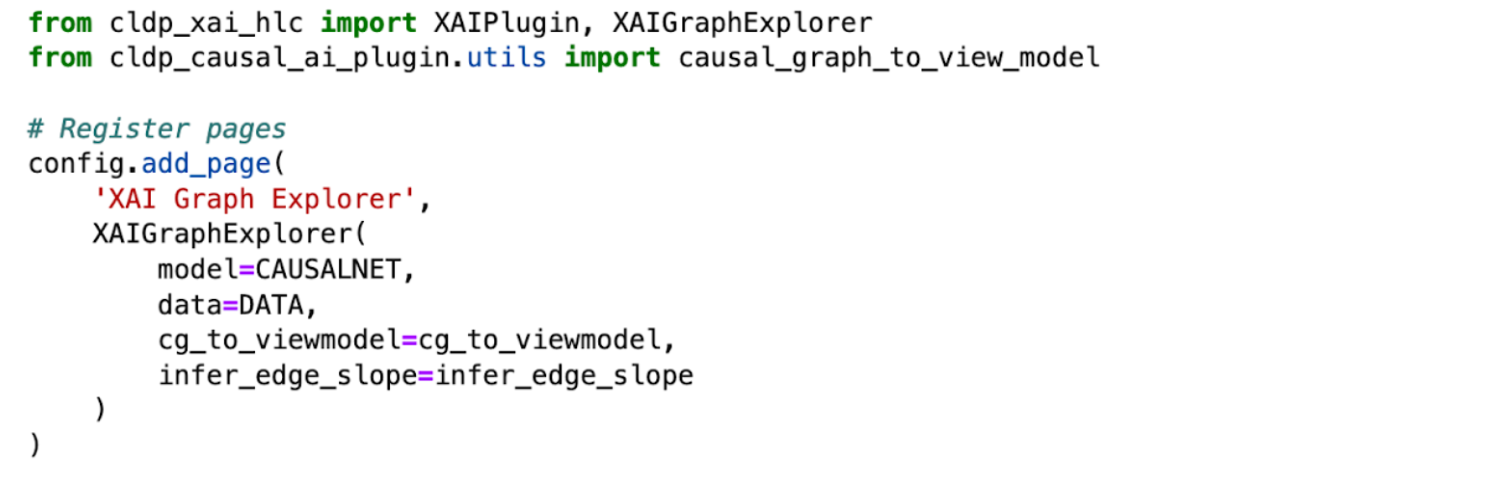
Figure 12: creation of high level component ‘XAI Graph Explorer’ in decisionOS
causaLens High Level Components library
causaLens has a library of high level components which can be accessed seamlessly with decisionOS, custom pages can also be built using Dara
Finally, the most important part of the whole process is ensuring the application can be deployed for use by business stakeholders. For this, data scientists can simply use the causaLens cldp-runtime image to develop an app natively and have it automatically run on decisionOS.
The application is now ready to be used by sales and marketing teams to improve customer retention across the enterprise.
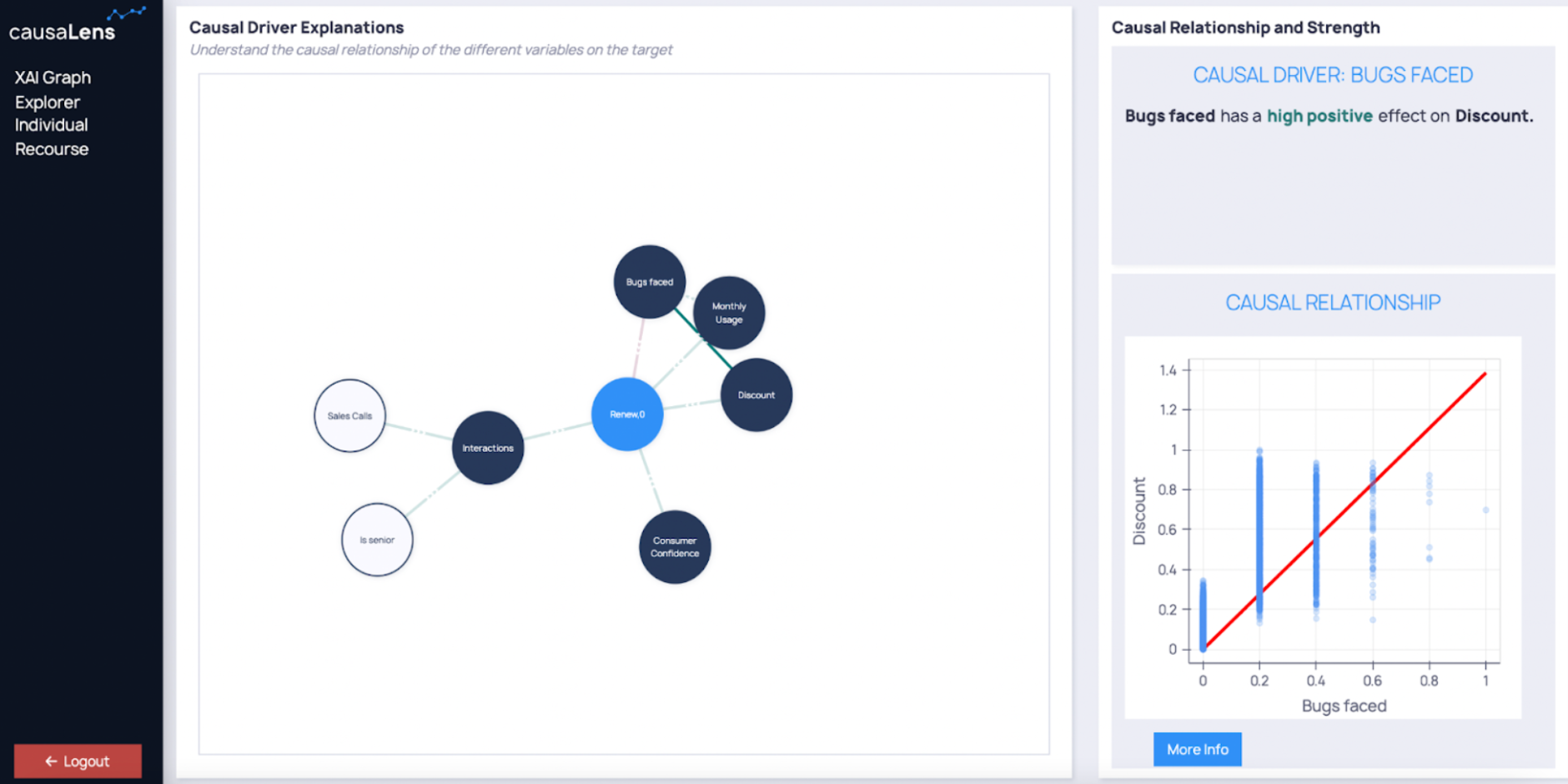
Figure 13: High-level Causal AI components in decisionOS
Conclusion
Causal customer retention decision workflows offer significant benefits over more
traditional predictive models by providing actionable recommendations
to business stakeholders. Interventions to retain customers can be applied
at the individual level and the model can also outline when budget should
not be spent as the cost of saving a customer will outweigh the lifetime value
(or any other threshold that the user applies).
decisionOS allows causal customer retention decision workflows to be
implemented, using the latest causality research, and deployed seamlessly
so that they can be used by business stakeholders to enhance
enterprise decision-making.
